SaaS短链接
1. 什么是SaaS短链接
短链接(Short Link),是指将一个原始的长URL 通过特定的算法或服务转化为一个更短,更易于记忆的URL。短链接通常只包括几个字符,而原始长URL可能会非常长
短链接的原理非常简单,通过一个原始连接生成几个相对短的连接,然后通过访问短链接跳转到原始链接
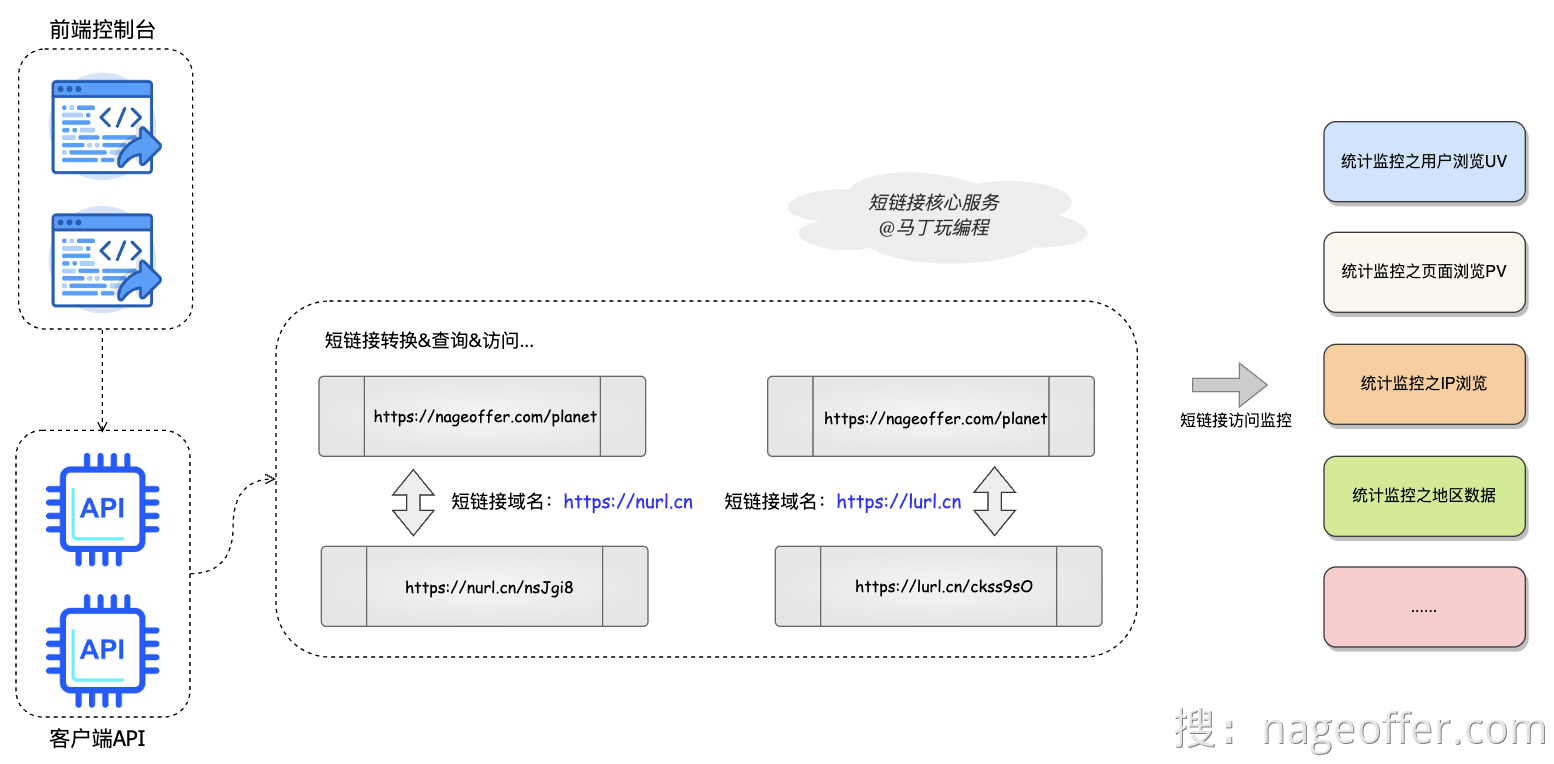
- 如下图,就是将长的URL转化为短链接URL

alt 短链接核心服务
- 如下图,就是将长的URL转化为短链接URL
如果更细节一点的话,就是:
- 生成唯一标识符:输入或提交长URL,会生成一个唯一的标识符或短码
- 将标识符与长URL关联:将这个唯一标识符与用户提供的长 URL 关联起来,并将其保存在数据库或者其他持久化存储中。
- 创建短链接:将生成的唯一标识符加上短链接服务的域名(例如:http://short.link/)为前缀,构成一个短链接
- 重定向:当用户访问该短链接时,短链接服务会收到请求并根据唯一标识符查询相关的长连接,然后用户重定向到这个长URL
- 跟踪统计:一些长连接服务还提供访问统计和分析功能,记录访问量,来源,地理位置
短链接的真实案例:
- 例如营销短信,里面就是短链接
alt 短链接案例
- 例如营销短信,里面就是短链接
主要作用包括以下几个方面
- 提升用户体验:用户更容易记忆和分享短链接,增强了用户的体验。
- 节省空间:短链接相对于长 URL 更短,可以节省字符空间,特别是在一些限制字符数的场合,如微博、短信等。
- 美化:短链接通常更美观、简洁,不会包含一大串字符。
- 统计和分析:可以追踪短链接的访问情况,了解用户的行为和喜好。

2. 技术架构
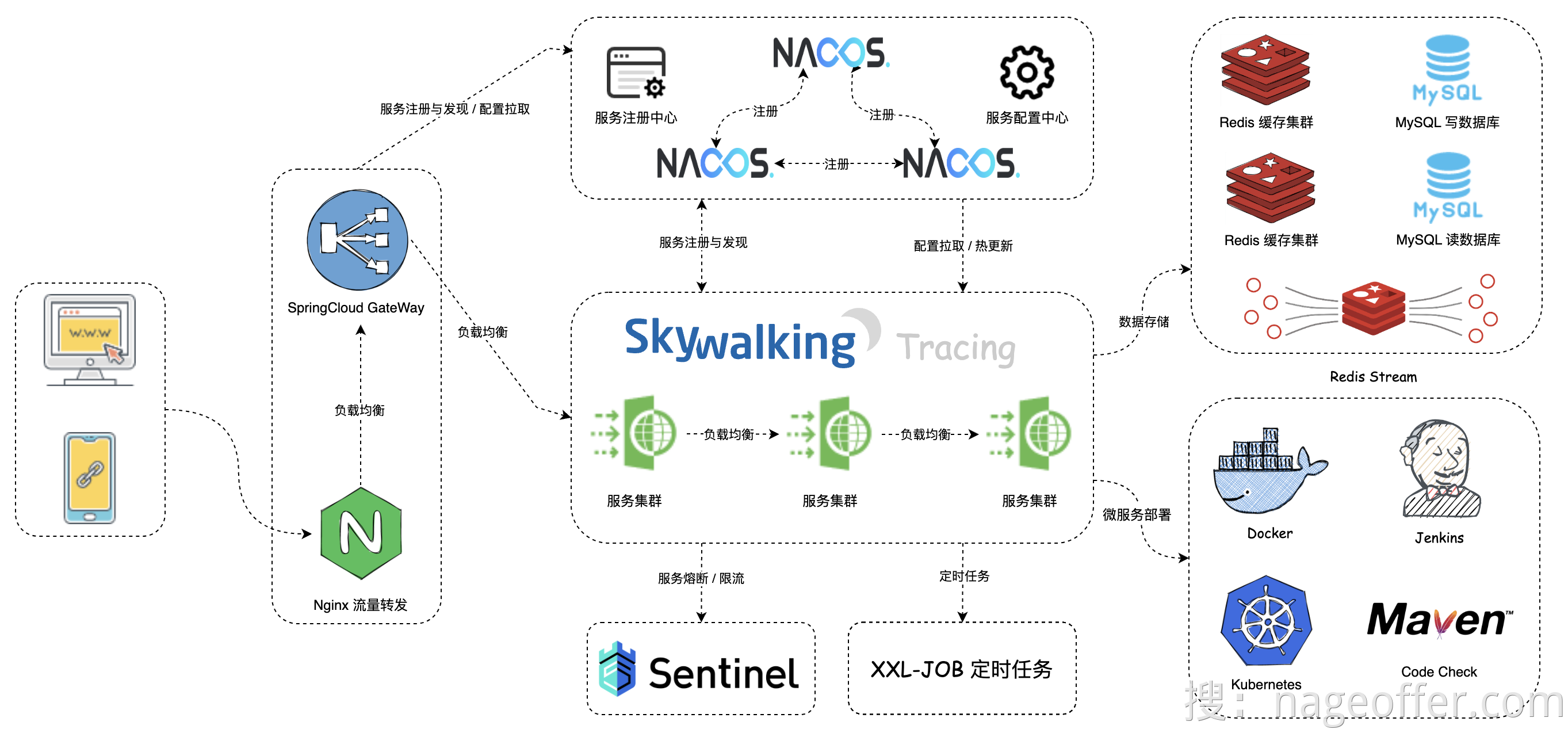
系统设计中,采用JDK17 + SpringBoot3 + SpringCloud微服务架构,构建高并发,大数据量下仍然能提供高效可靠的短链接生成服务
下图为SaaS短链接的架构图
alt 短链接架构图 接下来我们来创建该架构
- 创建Maven项目就不多赘述了,这里Java版本要是JDK17
- 需要注意的是这里的工件ID是
shortlink-all,代表着是整个项目的父模块
- 配置父模块
pom.xml
- 其中要说的是,添加
<packaging>pom</packaging>,让这个配置文件成为主项目的配置文件,不参与打Jar包等行为
1 |
|
添加微服务子模块项目
- 共有三个子模块需要创建
admin后台管理模块project项目模块gateway网关模块
- 这里工件ID设置成
shortlink-admin/project/gateway - 可以将所有子模块的的
pom.xml文件里的properties删除,因为已经继承了父模块的配置。
- 共有三个子模块需要创建
下面是admin/project子模块的项目架构
- gateway模块只是网关模块,不需要项目架构
- 需要注意的是romote是远程调用的的包,里面的DTO是远程给别的模块使用的,而本模块的DTO是本模块使用的。
1 | shortlink-admin/project |
- 给子模块添加springboot启动服务
- 先添加pom依赖
- 因为在父模块已经指定了这个依赖的版本,所以这里不需要二次指定
1
2
3
4<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>- 然后编写
application.yml文件- 这里admin端口
8082,project端口8081,gateway端口8080
- 这里admin端口
- 然后再每个项目里编写启动类
1
2
3
4
5
6
public class ShortLinkGatewayApplication {
public static void main(String[] args) {
SpringApplication.run(ShortLink子项目名称Application.class, args);
}
}- 最后直接启动,访问这些端口,发现显示
404No found,代表项目启动成功
- 先添加pom依赖
3. 接口文档
我们之前使用的是postman来发送接口请求,这里我们使用
Apifox来进行调用。为什么选择
Apifox?- 看他的介绍,就知道他多🐂了
- 就像男生都喜欢六合一洗发水一样,程序员也喜欢这种集合的工具
alt Apifox
这里我们来简单测试一下
- 新建一个配置环境
后台管理Dev,因为这里是admin模块,端口为8002,所以模块地址为: http://127.0.0.1:8002 - 新建一个GET请求,就叫根据用户名查找用户 请求地址是
/api/shortlink/v1/user/{username} - 在admin模块里的controller层写一个getMapping,如下
1
2
3
4
5
6
7/*
* 根据用户名查找用户
*/
public String getUserByUsername( String username){
return "hello" + " " + username;
} - 然后在Apifox上填写username(例如yin_bo_),查看返回是
hello yin_bo_ - 这里Apifox编码问题不识别中文,可以这样配置:
设置–>URL自动编码–>遵循WHATWG
- 新建一个配置环境

4. 用户模块
4.1 功能分析
- 我们这个项目主攻的是短链接,所以用户模块可以简化甚至不用,这里还是列举了该模块需要完成的功能:
- 检查用户名是否存在
- 注册用户
- 修改用户
- 根据用户名查询用户
- 用户登录
- 检查用户是否登录
- 用户退出登录
- 注销用户
4.2 用户表设计
- 我们这个项目主攻短链接,所以用户表可以设计的短一点
- ID使用bigint,以后使用雪花算法来设置唯一ID
- 这里的数据设置的varchar数量这么大是因为我们以后要对数据库的数据进行加密
1 | CREATE TABLE `t_user` ( |
4.3 查询用户信息功能
4.3.1 引入持久层框架和持久层配置
1 | <dependency> |
1 | spring: |
4.3.2 编写entity类
- 然后编写entity类,这里我推荐一个自动编写实体类的网站,可以将SQL转变为entity
- https://java.bejson.com/generator/
- 复习一下@Data注解:自动封装get/set方法,有参无参构造,hashcode什么的
- DO代表实体类(Domain Object)
1 | /* |
4.3.3 在启动类上加上持久层接口扫描器注解
1 | @MapperScan("com.yin_bo_.shortlink.admin.dao.mapper") |
4.3.4 写出映射接口
- 这里继承MyBatisPlus的
BaseMapper- 这个BaseMapper就是MyBatisPlus实现insert/update等一众ORM工具的类
1 | import com.baomidou.mybatisplus.core.mapper.BaseMapper; |
4.3.5 实现Service层的接口和实现类
- 先写用户服务的接口层
- 这里继承MyBatisPlus的IService接口,使通过泛型来读取实体类的数据
1 | public interface UserService extends IService<UserDO> { |
- 再去写用户服务的实现类
- 这里Impl规约性的写法:
- 继承ServiceImpl,第一个参数是UserMapper,第二个参数是实体类
- 实现服务的接口层,例如这里是UserService
- 注意这里一定要加上
@Service注解,让Spring管理接口层
- 这里Impl规约性的写法:
1 | /** |
4.3.6 写出用户响应的DTO
- 注意:这里密码,创建时间等等不需要让用户看到的数据千万不要写
- 一定要加上@Data注解!!!
1 | /** |
4.3.7 编写Impl实现方法
- 这里采用
hutool的BeanUtil方法,所以要引入这个依赖
1 |
|
4.3.8 在Controller层编写请求方法
注入方法的转变
- 注入一般都用注解注入
- 一般是@
Authwired,但是这个注解会造成风险 - 然后用的最多的就是
@Resource,但是这个注解在JDK17之后做了改版:- 导入的jar包变成了
import jakarta.annotation.Resource;
- 导入的jar包变成了
- 一般是@
- 所以这里推荐使用构造器注入
- 在控制器层代码里引入
@RequiredArgsConstructor注解 - 以后我们想注入方法的时候直接
private final 实现类名 方法名就可以了
- 在控制器层代码里引入
1 |
|
- 我们去数据库里创建一条数据
- 然后去Apifox里去发请求,发现返回成功了
1 | { |
4.3.9 功能相关的代码
1 | **/* |
1 | /* |
1 | /** |
1 | /* |
1 | public interface UserMapper extends BaseMapper<UserDO> { |
1 |
|
4.4 统一响应对象
在之前我们实现的功能中,如果查询的用户不存在,会返回null
- 这样用户就会有疑惑:是没查询到还是没有这个账号?
所以我们需要一个响应对象,可以全局返回状态
- 如果查询到就success,如果查询不到返回异常状态码
所以这里我们在common包里建一个convention(规约)包,在里面编写Result统一响应对象
- 这个Result基本都通用,这里直接给代码
1 | import lombok.Data; |
- 然后编写Controller层的代码,去设置查询的状态码,查询的状态等
1 | public Result<UserRespDTO> getUserByUsername( String username){ |
- 这里我们发现,每次写一个功能都要new Result… 是不是太繁琐了?而且规定上我们不能在Controller层代码里做各种判断对吧
4.5 全局异常码设计
这里我们学习一下对于异常码的设计
- 异常码是字符串类型
(这里我们的Result对象里也写了code是String类型),共五位 分为两个部分:错误产生来源+四位数据编号- 错误产生来源分为
A / B / CA表示错误来源于用户,比如参数错误,用户安装版本过低, 用户支付超时等B表示错误来源于当前系统,往往是业务逻辑出错,或者代码健壮性差C表示错误来源于第三方服务,比如CDN服务出错,消息投递超时
- 四位数字编号从0001到9999,大类之间的步长间距预留100
- 错误产生来源分为
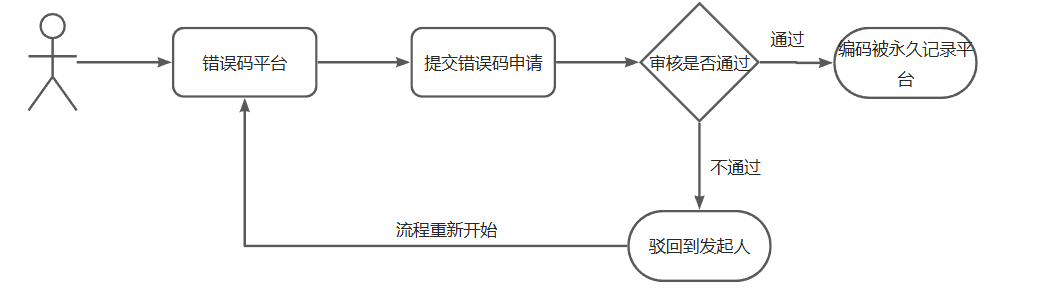
- 异常码不与公司业务架构和组织架构挂钩,那是如何规约的呢?
- 如下图,去平台上提交异常码申请,先到先申请原则,一旦申请,编号永久固定
alt 异常码规范申请图
- 如下图,去平台上提交异常码申请,先到先申请原则,一旦申请,编号永久固定
- 异常码是字符串类型
异常码分类:一级宏观错误码、二级宏观错误码、三级详细错误码。
| 错误码 | 中文描述 | 说明 |
| A0001 | 用户端错误 | 一级宏观错误码 |
| A0100 | 用户注册错误 | 二级宏观错误码 |
| A0101 | 用户未同意隐私协议 | |
| A0102 | 注册国家或地区受限 | |
| A0110 | 用户名校验失败 | |
| A0111 | 用户名已存在 | |
| A0112 | 用户名包含敏感词 | |
| xxx | xxx | |
| A0200 | 用户登录异常 | 二级宏观错误码 |
| A02101 | 用户账户不存在 | |
| A02102 | 用户密码错误 | |
| A02103 | 用户账户已作废 | |
| xxx | xxx |
| 错误码 | 中文描述 | 说明 |
| B0001 | 系统执行出错 | 一级宏观错误码 |
| B0100 | 系统执行超时 | 二级宏观错误码 |
| B0101 | 系统订单处理超时 | |
| B0200 | 系统容灾功能被触发 | 二级宏观错误码 |
| B0210 | 系统限流 | |
| B0220 | 系统功能降级 | |
| B0300 | 系统资源异常 | 二级宏观错误码 |
| B0310 | 系统资源耗尽 | |
| B0311 | 系统磁盘空间耗尽 | |
| B0312 | 系统内存耗尽 | |
| xxx | xxx |
| 错误码 | 中文描述 | 说明 |
| C0001 | 调用第三方服务出错 | 一级宏观错误码 |
| C0100 | 中间件服务出错 | 二级宏观错误码 |
| C0110 | RPC服务出错 | |
| C0111 | RPC服务未找到 | |
| C0112 | RPC服务未注册 | |
| xxx | xxx |
- 这里我们来实操一下:
- 在convention包里新建一个errorcode包,用来存错误码的信息
- 创建
BaseErrorCode**枚举(注意是枚举类型)**和IErrorCode接口,用来编写错误码信息
1 |
|
1 | /** |
- 然后这里写一个用户错误码枚举
1 | public enum UserErrorCodeEnum implements IErrorCode { |
- 然后在Controller层编写代码
1 | /* |
- 这时我们的代码就符合了异常码设计的规范
- 以后如果我们再想创建异常码枚举,就要去enums包里创建
4.6 全局异常拦截器
设想这种场景
- 我们在获取数据时没有判断它为空,就将获取的空数据给赋值了,这样就会发生NPE,我们需要给所有获取数据做非空判断
- 每个功能实现里都需要做try/catch拦截异常,太繁琐了
- 每次都要去Controller层给用户输出异常码和异常信息,太麻烦了
所以我们需要一个全局的可以拦截异常的工具,把异常都拦截下来并且日志留痕
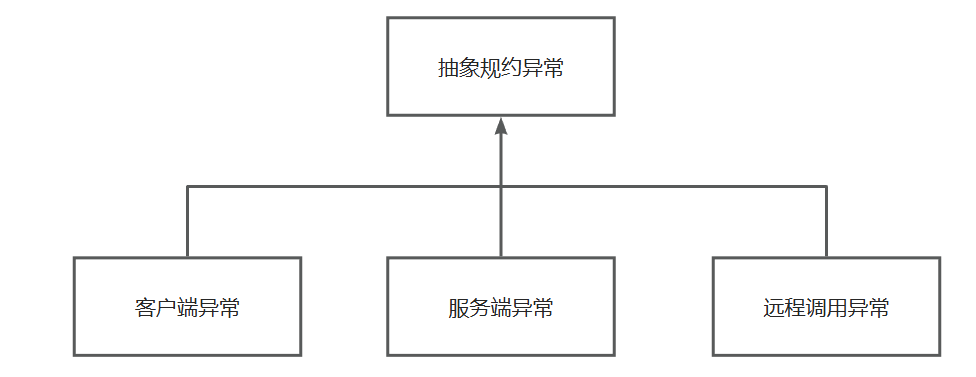
我们设计异常拦截器之前,先看一下异常体系:
- 将三种异常状态包裹成一个抽象规约的异常
alt 异常体系
- 将三种异常状态包裹成一个抽象规约的异常
接下来我们写下异常种类与规约代码:
1 | /** |
1 | /** |
1 | /** |
1 | /** |
4.7 用户敏感信息脱敏
- 我们需要对用户的敏感信息进行脱敏
- 例如身份证号:
138******99,中间加一段星号 - 用前端进行处理防不住控制台,所以我们要在后端返回数据的时候,把敏感信息脱敏
- 这里我们来将敏感信息序列化来进行脱敏
- 下面是手机号序列化器
- 这hutool包里已经封装了序列化类
DesensitizedUtil中的序列化工具mobilePhone,这个注解可以帮我们隐藏手机号中间的数字。
1 | package org.opengoofy.index12306.biz.userservice.serialize; |
- 这里我们设置一个断点,可以看到
mobliePhone的确将手机号脱敏了
- 然后jsonGenerator将脱敏后的字符串转化为JSON
alt 手机号脱敏过程

- 这里部署好手机号序列化器之后,我们只需要在DTO里手机号字段上面加一个JSON序列化器注解就好了
1 | /** |
- 之后我们再次请求数据,可以看到手机号已经脱敏了
1 | { |
4.8 查询用户名是否存在功能
当用户注册用户名的时候,我们更愿意当用户填写了用户名就显示是否被注册,而不是用户填了用户名,点击注册之后才返回名字已经被占用
- 实现这个需求就需要我们写一个检查用户名的功能
下面来编写功能吧
1 | /** |
1 |
|
1 | /** |
- 我们去请求/user/isOccupied/yin_bo_,因为数据库里有这个数据,所以data返回的是true,代表用户名已经存在
1 | { |
4.8 缓存策略
我们查询用户名代码没有设置缓存,如果海量请求打入数据库,数据库会直接宕机。
所以这里我们需要设置Redis缓存,以下为几个策略:
4.8.1 加载缓存
- 将数据库已有的用户名全部放到缓存里
- 存在的问题:
- 是否要设置数据的有效期?
- 要是数据永不过期,会导致Redis内存太高
4.8.2 布隆过滤器
什么是布隆过滤器?
- 是一种redis中的数据结构,用于快速判断一个元素是否存在于一个集合中
- 他包含一个
位数组和一组哈希函数,位数组的初始值为0,插入一个元素时,将该数据经过多个哈希函数映射到位数组的多个位置,并将这些位置的值设置为1 - 在查询一个元素是否存在是,会将该元素经过多个哈希函数映射到位数组上的多个位置,如果所有位置的值都为1,则该元素存在,如果任一位置为0,则元素不存在
使用布隆过滤器的流程:
1 | 用户发起调用,查看用户名是否可用 |
如果用户名存在,流程在Redis缓存中解决,是不存在数据库的流程的,所以性能更优秀。
布隆过滤器的优缺点:
优点:- 高效的判断一个元素是否数据一个大规模集合
- 节省内存
缺点:- 可能存在误判
布隆过滤器误判理解
- 布隆过滤器要设置初始容量,假如位数组能容忍一亿个数据,那么只有在一亿条数据左右才会发生误判
- 容量设置越大,冲突几率越低
- 布隆过滤器会设置预期的误判值,
布隆过滤器误判是否能容忍
答案是可以容忍:
如果用户想使用”aaa”作为名字,这时布隆过滤器发生了误判,让这个本来没有存在数据库里的用户名”aaa”显示被占用,这时用户也可以起个别的名字,这是可以容忍的
至于误判到”没找到”的可能性是不存在的,如果布隆过滤去说不存在,那么数据一定不存在。
4.9 布隆过滤器实战
- 引入redis和redisson依赖
- 这里我们就不造轮子自己写布隆过滤器了,直接用redisson提供的接口
1 | <dependency> |
- 配置Redis参数
1 | data: |
- 创建布隆过滤器配置
- 新建一个config包,下面新建一个
RBloomFilterConfiguration类 - 我们来尝试解读这段代码:
- 首先先用
redissonclient创建一个布隆过滤器,过滤器的名字是cachePenetrationBloomFilter。 - 过滤器的tryInit有两个参数:
- 第一个参数是
expectedInsertions,预估布隆过滤器存储的元素长度。 - 第二个参数是
falseProbability,运行的误判率 - 错误率越低,位数组越长,布隆过滤器的内存占用越大。
- 错误率越低,散列 Hash 函数越多,计算耗时较长。
- 这里推荐一个布隆过滤器计算网站: https://krisives.github.io/bloom-calculator
- 这里我们尝试一亿个用户名,0.1%的错误率,发现才只有100多M的占用
- 这是个非常优秀的性能。
- 第一个参数是
- 新建一个config包,下面新建一个
1 | /** |
- 使用布隆过滤器
- 通过构造器注入我们的用户注册布隆过滤器
- 然后在查询占用功能中直接返回布隆过滤器是否包含username
1 |
|
- 这里使用布隆过滤器有两种场景:
- 初始使用:注册用户时就向容器中新增数据,以后就不需要调用数据库了。
- 中途引用布隆过滤器:读取数据源的时候要将数据库中数据刷到布隆过滤器中。
- 这里我们刚开始就用来布隆过滤器,所以以后查询用户名不需要调用数据库。
4.10 用户注册功能
- 不多说,让我们先写出用户注册的基础代码:
- 这里用户的信息参数名使用requestParam,通俗易懂
- 在用户注册前要判断布隆过滤器里是否有被占用的用户名
- 用户注册后将用户名传给布隆过滤器
1 | /** |
1 |
|
1 | /** |
- 然后我们使用Apifox发送请求
1 | { |
- 我们可以发现用户存入数据库的信息并没有创建时间,更新时间,注销标志
- 这就需要MP的自动填充功能去实现
- 这里可以查阅 https://baomidou.com/guides/auto-fill-field/ 来看如何实现自动填充
- 需要我们建个
MetaObjectHandler类,在里面重写insertFill和updateFill - 注意:如果要在insert和update的时候都要写数据,就要在这两个方法里写
- 实现完这个类之后,我们需要在DO里给需要自动填充的参数加上注解
- 下面是FieldFill的枚举和实现功能的代码
- 注意,如果要在insert和update的时候都要写数据,必须注解上加上
INSERT_UPDATE
1 | public enum FieldFill { |
- 这里变量名改为
TimeMetaObjectHandler
1 |
|
1 | /* |
- 这里必须在数据库里给username建立唯一索引
- 因为我们的username判断全在redis里进行的,如果发生极小概率事件,比如主redis的数据还没复制给从redis就宕机了,这时没有接受完全数据的从redis变成了主机,就会丢失布隆过滤器里的数据。
1 | create unique index idx_unique_username |
4.11 分布式锁
布隆过滤器+设置唯一索引就能保证用户名不重复了。
但是短时间内有大量恶意请求都注册了相同的用户名
如果程序还没执行到将注册的名字返回给布隆过滤器,那么这么多用户名就会都访问到数据库,但因为有唯一索引,所以仍然不会重复。但是会对数据库造成不小的压力这里我们就要保证操作的原子性,比如使用Lua脚本
这里使用黑马点评用过的Redisson分布式锁,底层也是Lua脚本实现的
流程图如下:
alt 分布式锁防止缓存穿透 使用Redisson分布式锁代码:
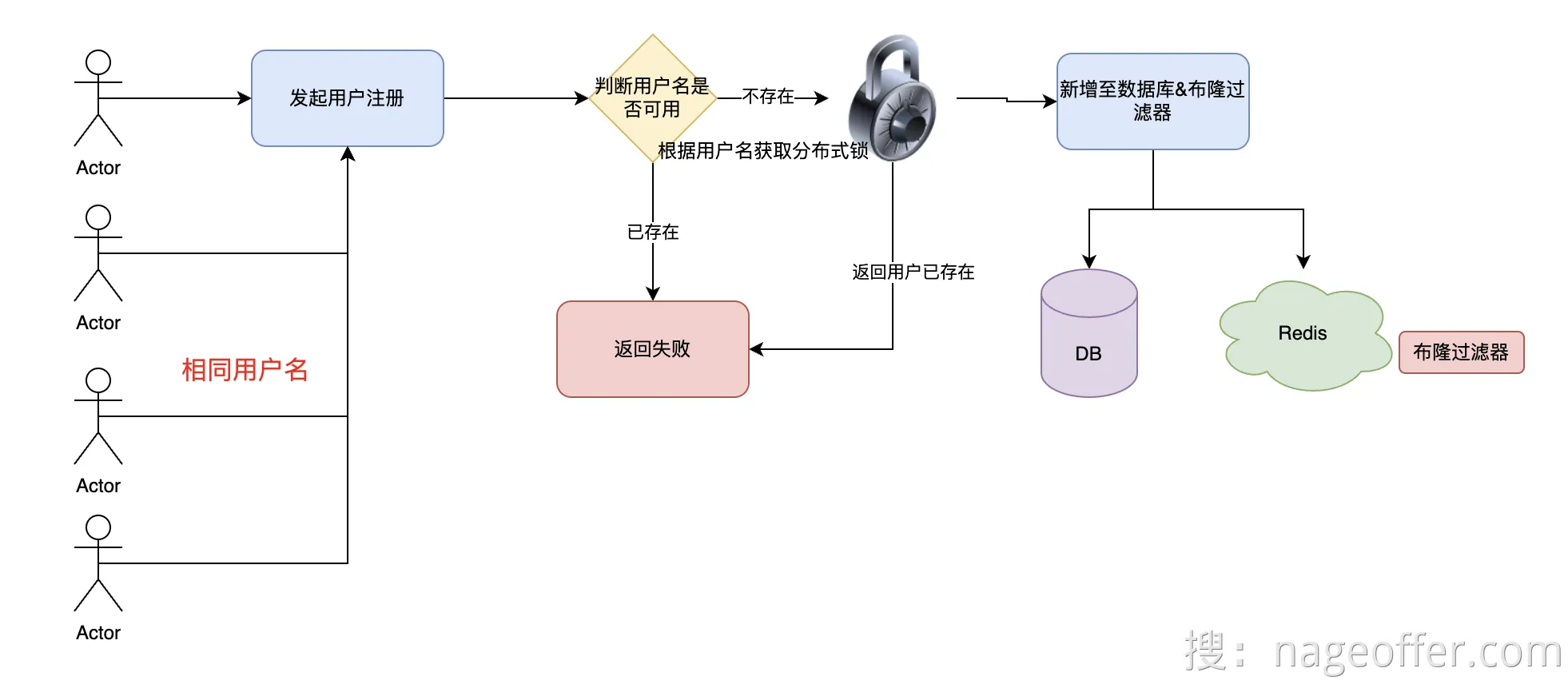
1 | private final RedissonClient redissonClient; |
- 如果有恶意请求发送大量不同用户名的信息进行注册,可以防住么:
- 答案是防不住,系统无法进行完全风控,只有通过类似于限流的功能进行保障系统安全。
4.12 用户数据分库分表
为什么要分库分表
- 我们SaaS化的短链接系统会有海量用户信息被保存,这时我们就需要对数据进行分库分表。
什么是分库分表
分库和分表都有两种模式,垂直或者水平。
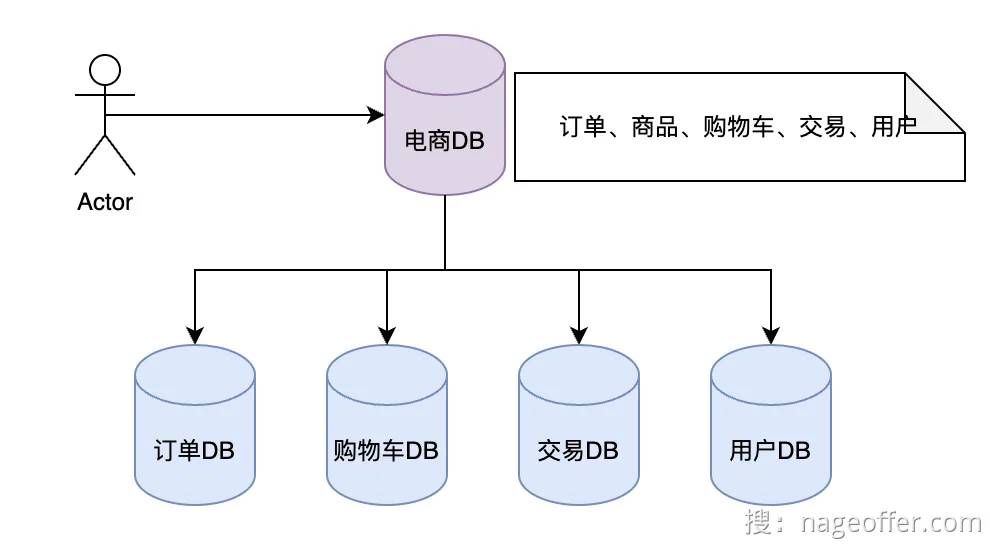
分库:
- 垂直分库:将不同业务进行分库,比如订单都存到一个库,用户都存到一个库
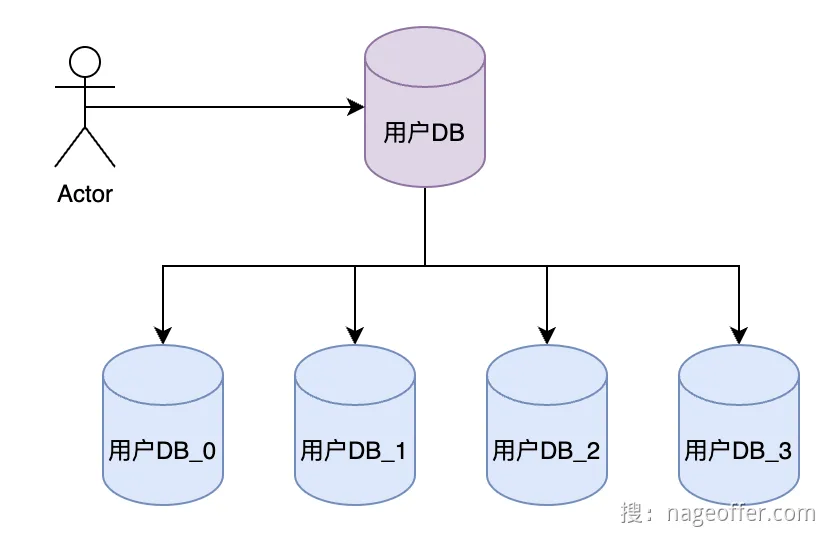
alt 垂直分库 - 水平分库:一个业务拆分成多个库
alt 水平分库
- 垂直分库:将不同业务进行分库,比如订单都存到一个库,用户都存到一个库
分表:
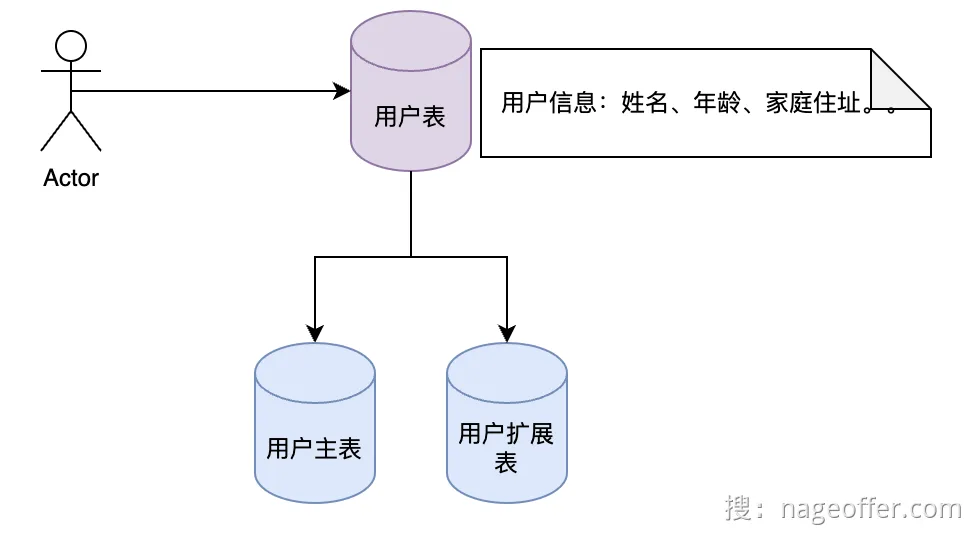
- 垂直分表:按照业务维度进行拆分,将不常用信息放在一个拓展表
- 比如用户的个人简介这种TEXT文本就要放到拓展表
- 垂直分表:按照业务维度进行拆分,将不常用信息放在一个拓展表
* 水平分表:一个业务拆分成多个表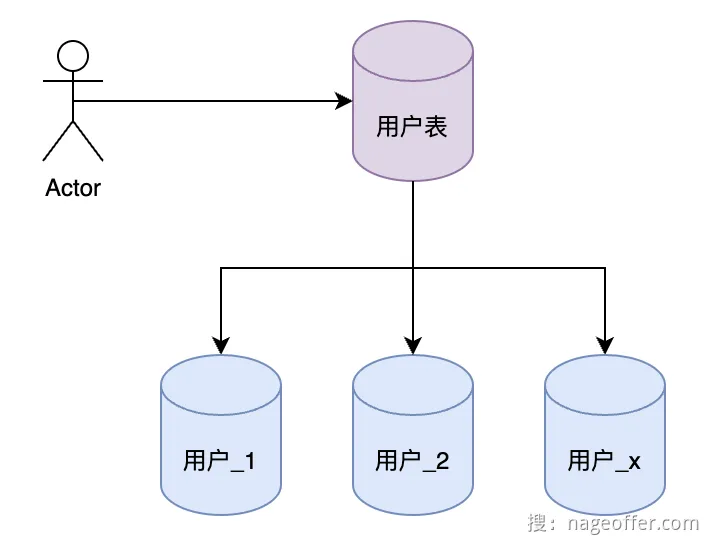
- 分库分表的场景
- 什么场景下分表:
- 数据量过大或者数据库表对应的磁盘文件过大(不利于备份)
- 什么场景下分库:
- 连接不够用,假设数据库服务器支持4000个数据库连接,一个服务连接池最大十个,假如有40个节点,已经占用400个数据库连接。假如这种服务有10个,那么数据库服务器连接就不够了
- 什么场景下分表:
4.13 ShardingSphere
分片键
用于将数据库(表)水平拆分的数据库字段。
分库分表的分片键(
Sharding Key)是一个关键决策,他直接影响了分库分表的性能和可拓展性。以下是一些选择分片键的关键因素:- 访问频率:选择分片键应考虑数据的访问频率,将经常访问的数据放在同一个分片上,可以提高查询性能和调低跨分片查询的开销。
- 数据均匀性:分片键应该保证数据的均匀分布在各个分片上,避免出现热点数据集中在某个分片上的情况。
- 数据不可变:一旦选择了分片键,这个键就应该是不可变的,不能随着业务的变化而频繁修改。
这里我们将分片键设置为id
引入ShardingSphere-JDBC到项目
- 引入依赖
1
2
3
4
5<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core</artifactId>
<version>5.3.2</version>
</dependency>- 定义分片规则
1
2
3
4
5
6spring:
datasource:
# ShardingSphere 对 Driver 自定义,实现分库分表等隐藏逻辑
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
# ShardingSphere 配置文件路径
url: jdbc:shardingsphere:classpath:shardingsphere-config.yaml- 这里我们要另外写一个shardingsphere的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/shortlink?characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&serverTimezone=GMT%2B8
username: root
password: root
rules:
- !SHARDING
tables:
t_user:
# 真实数据节点,比如数据库源以及数据库在数据库中真实存在的
actualDataNodes: ds_0.t_user_${0..15}
# 分表策略
tableStrategy:
# 用于单分片键的标准分片场景
standard:
# 分片键
shardingColumn: id
# 分片算法,对应 rules[0].shardingAlgorithms
shardingAlgorithmName: user_table_hash_mod
# 分片算法
shardingAlgorithms:
# 数据表分片算法
user_table_hash_mod:
# 根据分片键 Hash 分片
type: HASH_MOD
# 分片数量
props:
sharding-count: 16
# 展现逻辑 SQL & 真实 SQL
props:
sql-show: true
逻辑表和真实表
- 我们来看一下这段代码
1
2
3
4tables:
t_user:
# 真实数据节点,比如数据库源以及数据库在数据库中真实存在的
actualDataNodes: ds_0.t_user_${0..15} - 这里涉及了逻辑表和真实表的概念
- 逻辑表就是t_user 而真实表是我们的t_user_数字。
- 为什么要这样设计?因为我们在查询表的时候要有逻辑标识,比如我们的DO里这样写
1
- 这就意味着我们查询的逻辑表是t_user,而shardingsphere让他实际查询的是我们的真实表
- 我们来看一下这段代码
- 发送请求,查看控制台
- 我们发送注册请求之后,发现数据被存到其中的某一个表中,我们来查看控制台
- 发现是先查询的逻辑表t_user,再通过shardingsphere的分片键进行分表查询
- 我们发送注册请求之后,发现数据被存到其中的某一个表中,我们来查看控制台
1 | SQL: INSERT INTO t_user |
4.14 加密存储敏感信息
如果是上市项目我们不可能将明文敏感信息直接存放到数据库,如果这样数据库泄露之后将敏感信息泄露了。
我们应该将用户的敏感信息进行加密处理。
一共有三种加密类型
- 对称加密
- 可逆,通常只需要一把密钥,用来保证后端的数据机密性
- 非对称加密
- 可逆,相比于对称加密,接收者会多一把私钥用于解密,常用于网络数据传输
- 哈希函数
- 不可逆,无密钥,通常用于用户注册
- 对称加密
这里我们的用户注册的信息要去加密,这里采用以下的加密方式:
- 手机号,身份证号等敏感信息,使用对称加密,也就是说后台可以通过密钥解密去获取用户手机号等。
- 用户密码这种绝对敏感信息,使用哈希函数,一旦加密,那么没有人能够解密,如果用户自己也忘了密码,则不可能被找回
想想QQ的忘记密码,也是让你新创建个密码而不是告诉你旧的密码,因为被哈希函数加密了,QQ后台也不知道密码。
4.14.1 AES加密算法
我们手机号用的对称加密是AES加密算法
AES作为对称加密算法,加密和解密用的是同一个密钥。
AES有两种加密模式:ECB和CBC
ECB:将数据分成不同的数据块,发送方和接收方同时用一个密匙进行加密和解密。CBC:除了密匙之外,增加了一个参数初始化向量(IV),这个IV通常是随机的。并且IV与密文要一起传输给接收者。
密钥和IV都是加密过程中的参数,目的是为了同一明文能够生成不同的密文(例如加密的是姓名,两个人的姓名一样,这时我们如果用同一个密钥去加密,加密的结果会一样,如果引入随机的IV,那么就不一样了)。
Padding填充
- AES是块加密算法,一次处理一个固定大小的数据块 (比如说16字节),如果数据不是16字节的整数倍,那么我们就需要去给数据做填充了
- 这里我们使用的是
PKCS5Padding填充方式,若数据块大小是16个字节,后面缺N个字节,那么它会帮我们填充N个N的16进制数字
我们来具体实现一下吧
我们采用的是CBC模式,因为我们这里加密的是手机号,每个人的手机号不一样,所以我们的IV先填个固定值
- 将AES设置封装,注意这里密钥和IV都写在代码里,这是不符合生产规范的,到时候需要修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class UserInfoAESKey {
private final AES aes;
public UserInfoAESKey() {
this.aes = new AES(
Mode.CBC,
Padding.PKCS5Padding,
"yin_bo_shortlink".getBytes(StandardCharsets.UTF_8),
"yin_bo_shortlink".getBytes(StandardCharsets.UTF_8)
);
}
}- 在注册功能里对手机号进行AES对称加密
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//构造器注入userInfoAESKey AES设置
private final UserInfoAESKey userInfoAESKey;
...
...
...
public void register(UserRegisterReqDTO requestParam) {
...
...
...
//对手机号进行加密,将加密后的手机号传给实体类
if (StringUtils.isNotBlank(requestParam.getPhone())) {
String encryptedPhone = userInfoAESKey.getAes().encryptBase64(requestParam.getPhone());
userInfo.setPhone(encryptedPhone);
}
...
}
4.14.2 BCrypt哈希函数
- 哈希函数不用密匙进行加密,而是使用盐值(Salt)进行哈希计算,注意不是加密
- 被盐值进行哈希的数据是不能被解密的。这也是哈希函数绝对安全的原因。
- 被哈希的数据里面包括哈希结果和盐值,其中盐值是唯一且可以直接发给接收者的。但是因为不能解密,所以接收者如果没有正确数据,即使得到盐值也没用。
- 我们用户登录时从数据库中获取哈希值里的盐值,使用盐值将用户输入的密码进行哈希,再去跟哈希值做比对,方可登录成功,这里使用Hutool集成的工具,我们甚至不用去获取盐值,直接使用
checkpw即可。
在注册业务里对密码进行哈希处理
1
userInfo.setPassword(BCrypt.hashpw(requestParam.getPassword(), BCrypt.gensalt()));
在登录业务里对用户输入的密码进行比对
1
2
3if (!BCrypt.checkpw(password, passwordInDB)) {
throw new ClientException(UserErrorCodeEnum.USER_PASSWORD_ERROR);
}
4.15 用户信息修改功能
这里实现需要说一下,修改用户名和修改其他的信息我们要分成不同的模块去做。
- 因为我们的username是唯一的,不允许重复的,别人去查我们的用户信息是通过查username去查的。
- 所以这里我们的username是不支持频繁的修改的
- 而其他的信息都是可重复的,用户想怎么修改就怎么修改。
- 因为我们的username是唯一的,不允许重复的,别人去查我们的用户信息是通过查username去查的。
现在我们项目还没有完善,无法通过用户的登录态(比如JWT,redis里的用户信息缓存)去获取用户id,所以这里我们先使用前端获取的id,并且在请求DTO表上加上id字段,等下一部分敲完我们就可以将id字段删除。
- 这里为了防止有人恶意多次修改用户名对服务器进行压测,我们之后可以设置修改时间,比如一年只能修改一次,不到一年不能再次修改
首先是修改用户信息的功能
1 | /** |
1 | void updateInfo( UserUpdateInfoReqDTO requestParam); |
1 |
|
1 | /** |
- 接下来是修改用户username的功能
1 | /** |
1 | void updateUsername(UserUpdateUsernameReqDTO requestParam); |
1 |
|
1 | /** |
4.16 用户登录功能
需求:用户发起登录请求,发送了用户名和密码,我们经过逻辑判断给用户前端发送token
优化点:
- token与用户的信息将存入redis缓存,设置过期时间,避免大量堆积。
- 为了避免用户恶意重复登录为数据库增压,这里使用redis的hash结构,将key设置为用户名,若下次该用户名的用户再次登录,会从redis里进行比对,如果等同返回用户已登录。
1 | /** |
1 | String login(UserLoginReqDTO requestParam); |
1 |
|
1 | /** |
4.17 用户登出功能
- 没啥好说的
1 | void logout(String username, String token); |
1 |
|
1 |
|
5. 短链接分组
假如用户创建了10个短链接,短链接都是不同的功能,就需要去将他们进行分组
这就是我们短链接分组需要完成的功能。
功能分析:
- 增加短链接分组
- 修改短链接分组(只能修改名称)
- 查询短链接分组集合(短链接分组最多10个)
- 删除短链接分组
- 短链接分组排序
5.1 创建分组DB
- 短链接分组肯定和用户这种数据量比不了,所以这里我们不再进行分表,只创建一个表用来存分组信息
- 下面是SQL语句
- 唯一索引使用gid和username进行约束,也就是一个用户的分组的gid唯一,不同用户可以有相同gid的分组
- gid作为标识码,使用随机生成六位英文数字来作为分组的标识。
1 | CREATE TABLE `t_group` ( |
5.2 初始化短链接分组功能
- 没啥好说的,用java自动生成代码的网站通过SQL语句来生成实体类代码
- 下面是初始化的代码
1 | /** |
1 | /** |
1 | /** |
1 | /** |
1 | /** |
5.3 新增分组功能
这里用户的分组的gid不能相同,但是不同用户的不同分组的gid可以相同,所以唯一索引是
{gid,username}。从上下文获取username的功能我们还没有去实现,先做个todo
这里使用hutool的
randomStringUpper来生成随机的gid。为了防止gid相同,这里通过
DupliocateKeyExceptioon捕获唯一索引冲突异常。- 若有重复的gid,会catch这个异常,然后我们再生成gid进行判断
- 最大尝试三次,如果三次gid还是重复,直接抛出异常
GROUP_SAVE_ERROR
下面是功能实现代码
1 | /** |
1 |
|
1 |
|
5.4 查询分组功能
- 这里是查找用户的所有短链接分组功能
- 但是如果用户有几千个分组,那查起来是不是太多了
- 这里我们使用MybatisPlus的page功能来对数据进行简单分页
- 建个分页拦截器,然后在page里传两个参数,一个是查询的页数,另外一个是一页的最大数量
- 这里我们还没写用户上下文,对于用户面先用isNull判断
1 | /** |
1 | public List<GroupRespDTO> listGroup() { |
1 |
|
1 |
|
1 |
|
5.5 用户上下文
这里我们简述一下实现过程:
- 在UserConfiguration里注册一个用户信息传递过滤器。过滤范围为
/*,也就是说是全局过滤器 - 当用户发起请求,过滤器就会被执行,读取请求的Header,然后在Redis里查询用户的信息。
- 将用户的信息反序列化为UserInfoDTO,然后通过
UserContext类的setUser方法将用户信息存入TTL。 - 这时就可以从
UserContext里的get方法获取用户信息了。 UserContext在请求发送完后会调用removeUser方法去删除用户信息,避免用户信息泄露
- 在UserConfiguration里注册一个用户信息传递过滤器。过滤范围为
TTL(TransmittableThreadLocal)
- 阿里开源的ThreadLocal,能支持线程池复用和异步任务场景下上下文传递
这里放行用户登录的地址,其他的地址只要发起请求,都需要检测是否登录,也就是Header里携带Token和username
在Fliter里不能直接抛出我们规定的错误码,因为我们的错误码只能在Controller和Service层调用
- 所以这里我们再定义一个异常。
1 | /** |
1 | public final class UserContext { |
1 | /** |
1 | /** |
- 然后我们去使用上下文获取用户名实现分组功能
1 |
|
我们在Apifox里设置header
- username : …
- token : …
然后发送请求,即可看到该用户的分组信息
然后这里我们就可以修改登出功能了
- 原本的登出功能需要传参token和username
- 这里不再传参,需要验证用户是否登录
- 然后再从用户上下文中获取用户名,然后实现登出功能
1 | /** |
1 | void logout(); |
1 |
|
5.6 修改/删除/排序分组功能
- 这三个分组实现起来很简单,这里就不再说了
1 |
|
1 | /** |
1 |
|
1 |
|
6. 短链接管理
6.1 功能分析
- 短链接跳转原理
- 创建短链接表
- 新增短链接
- Host添加域名映射
- 分页查询短链接集合
- 编辑短链接
- 将短链接删除(回收站)
6.2 短链接跳转原理
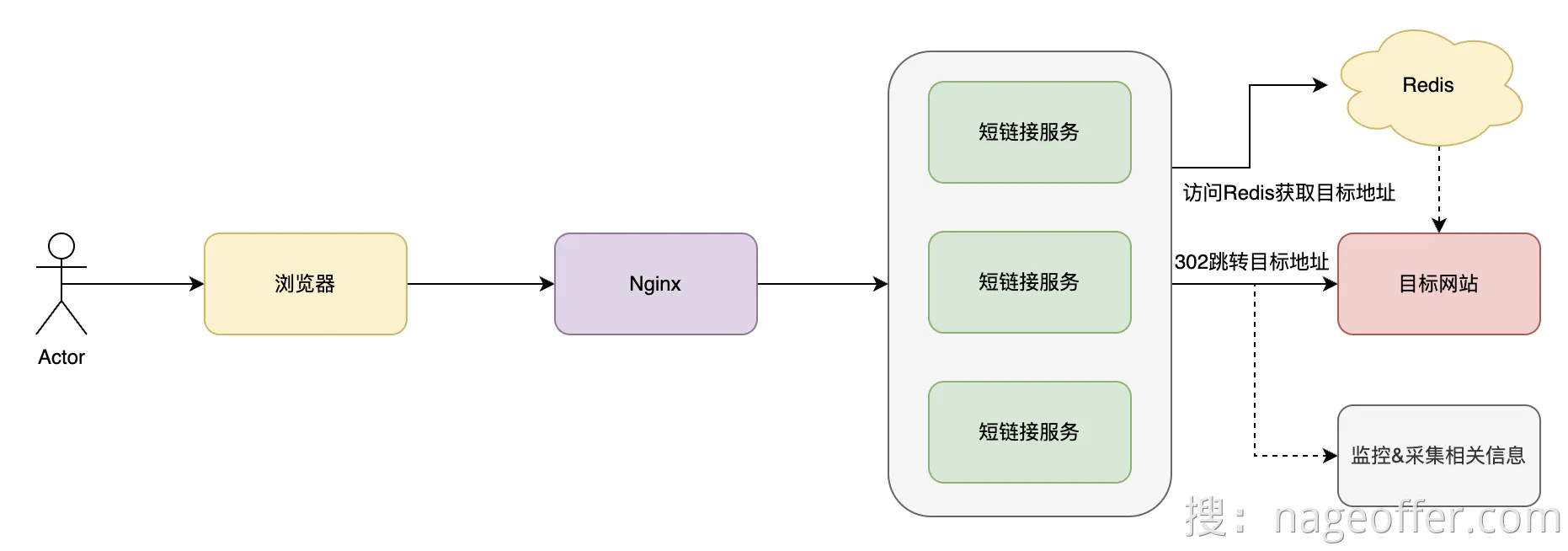
一般以3XX 开头的状态码代表重定向,表示页面发生了转移,需要重定向到对应的地址中去,两者的区别:
301:表示永久性转移(Permanently Moved)
- 301只能访问短链接一次,之后都直接跳转到短链接,不能采集信息,所以这里用302
302:表示临时性转移(Temporarily Moved)
- 302每次都会去后端拿取地址,方便进行用户数据采集
短链接需要怎么确保唯一性?
- 全局唯一:单一短链接在所有域名下唯一,全平台唯一
- 域名下唯一:单一短链接仅确保域名下唯一。
6.3 短链接结构
短链接的结构:
alt 短链接结构
由协议+短链接域名+短链接组成这里生成最后的短链接数字实现最为重要
- 这里我们使用Base62编码短ID生成算法来生成短链接
Base62编码短ID生成算法是什么
- 假如给一个短链接使用10进制数来编号
- 然后将这个10进制数通过Base62编码来转换成62进制数字(62代表大小写英文字母+数字的数量)
- 这样就可以对短链接进行数据压缩,假如我这个10进制数为100亿,如果直接使用他会让连接变得很长,我们将其转化为62进制数字就可以很短
- 假如给一个短链接使用10进制数来编号
这里我们如果设置短链接最多只有六位,那么对于短链接可以表示的最大组合数量为:
- N = 6,组合数为
62 ^ 6 = 56_800_235_584,568 亿左右
- N = 6,组合数为

6.4 配置project模块
- 这里我们的短链接业务不能再去后台管理模块做了,这里我们配置中台模块(peoject)
修改配置文件
- Maven配置就不说了,直接将pom.xml的依赖复制过来
- 这里我们先不使用
shardingsphere分表,先正常写配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19server:
port: 8001
spring:
datasource:
username: root
password: zhou123quan
url: jdbc:mysql://localhost:3306/shortlink?characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&serverTimezone=GMT%2B8
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
connection-test-query: select 1
connection-timeout: 20000
idle-timeout: 300000
maximum-pool-size: 5
minimum-idle: 5
data:
redis:
host: 127.0.0.1
port: 6379
password: zhou123quan添加状态码功能代码
- 没啥好说的,将我们状态码功能的代码添加到project模块
- 一般来说这种代码都要打jar包然后引入依赖,这里因为我们的模块比较少,所以直接复制就行。
- 将以下的文件复制到project模块
/common/convention/errorcode/BaseErrorCode.java/common/convention/errorcode/errorcode/IErrorCode.java/common/convention/exception/AbstractException.java/common/convention/exception/ClientException.java
5./common/convention/exception/RemoteException.java/common/convention/exception/ServiceException.java/common/convention/Result.java/common/convention/Results.java
添加MP的自动填充功能代码
- 将
/config/TimeMetaObjectHandler引入project模块
- 将
6.5 短链接表DB
URI (统一资源标识符):最宽泛的概念,用来唯一标识一个资源。URL 和 URN 都是 URI 的子集。
URL (统一资源定位符):它不仅标识资源,还指明了如何定位(找到)这个资源,即提供了访问机制(协议+位置)。
1 | CREATE TABLE `t_link` ( |
6.6 新增短链接
- 现写咱们的DB写一下dao层的代码吧
- 注意:
describe是mysql的关键字,我们不能直接使用,所以要转义以下,也就是增加这个注解@TableField(value = "describe")- 这里我们的启用标识
enableStatus也需要自动填充为0,所以我们要在MP填充配置里添加这段代码this.strictInsertFill(metaObject, "enableStatus", Integer.class, 0);
1 | /** |
1 |
|
然后我们来写一下生成短链接结构的代码
- 这里我们采用BASE62编码
62表示大小写英文字母+数字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/**
* HASH 工具类
*/
public class HashUtil {
private static final char[] CHARS = new char[]{
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'
};
private static final int SIZE = CHARS.length;
private static String convertDecToBase62(long num) {
StringBuilder sb = new StringBuilder();
while (num > 0) {
int i = (int) (num % SIZE);
sb.append(CHARS[i]);
num /= SIZE;
}
return sb.reverse().toString();
}
public static String hashToBase62(String str) {
int i = MurmurHash.hash32(str);
long num = i < 0 ? Integer.MAX_VALUE - (long) i : i;
return convertDecToBase62(num);
}
}- 这里我们采用BASE62编码
接下来来实现我们新增短链接的业务代码吧
1 | /** |
1 | /** |
1 | /** |
1 | /** |
1 | /** |
- 然后我们通过接口发送请求
1 | { |
- 发现成功插入了
1 | SQL: INSERT INTO t_link ( id, domain, short_uri, full_short_url, origin_url, gid, enable_status, created_type, valid_date_type, `describe`, create_time, update_time, del_flag ) VALUES ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ? ) |
6.7 优化功能
修复短链接大小写问题
- 假如我们要查短链接为
wsakjd的URL,但是把短链接输成了wsakjD,还是能查询到我们想要的数据。- 这是因为MySQL的UTF-8是忽略大小写的。
- 所以这里我们需要修改short_uri的排序规则为
utf8mb4_bin
- 假如我们要查短链接为
优化新增短链接
这里如果很多人用同一个URL来生成短链接,那么生成的短链接冲突,会导致一个url只能生成一个短链接
那么我们就需要给URL增加扰动,来确保同一个URL可以生成不同的短链接
这时我们需要确保短链接不能冲突,直接查询数据库太耗性能,这里我们也引用布隆过滤器。
布隆过滤器可能会误判,所以在添加到数据库时查询唯一索引是否冲突,如果冲突返回前端,让用户重试。
添加布隆过滤器代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/**
* 布隆过滤器配置
*/
public class RBloomFilterConfiguration {
/**
* 防止短链接创建查询数据库的布隆过滤器
*/
public RBloomFilter<String> ShortUriCreateCachePenetrationBloomFilter(RedissonClient redissonClient) {
RBloomFilter<String> cachePenetrationBloomFilter = redissonClient
.getBloomFilter("shortUriCreateCachePenetrationBloomFilter");
cachePenetrationBloomFilter.tryInit(100000000L, 0.001);
return cachePenetrationBloomFilter;
}
}- 修改后的新增短链接代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
private final RBloomFilter<String> ShortUriCreateCachePenetrationBloomFilter;
public ShortLinkCreateRespDTO createShortlink(ShortLinkCreateReqDTO requestParam) {
//将原始url哈希成短链接
String shortLink = generateSuffix(requestParam);
String fullShortLink = requestParam.getDomain() + "/" + shortLink;
//将请求参数转化成 shortLinkDO 实体类
ShortLinkDO shortLinkDO = BeanUtil.toBean(requestParam, ShortLinkDO.class);
//设置实体类短链接和 完整url
shortLinkDO.setShortUri(shortLink);
shortLinkDO.setFullShortUrl(fullShortLink);
try{
//将实体类存储到数据库
save(shortLinkDO);
}catch (DuplicateKeyException e){
log.warn("短链接:{} 重复入库",fullShortLink);
throw new ServiceException("生成短链接繁忙,请稍后重试");
}
//新建相应参数的实体类
ShortLinkCreateRespDTO respParam = new ShortLinkCreateRespDTO();
//给相应实体类设置 gid 完整url 原始url
respParam.setGid(shortLinkDO.getGid());
respParam.setFullShortUrl(shortLinkDO.getFullShortUrl());
respParam.setOriginUrl(shortLinkDO.getOriginUrl());
return respParam;
}
private String generateSuffix(ShortLinkCreateReqDTO requestParam) {
String originUrl = requestParam.getOriginUrl();
String domain = requestParam.getDomain();
int attempt = 0;
while (attempt < 10){
//获取当前时间
String timeStr = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyyMMddHHmmssSSS"));
//在哈希时加入扰动(这里是时间),使其能生成不同的suffix
String suffix = HashUtil.hashToBase62(originUrl + "#" + timeStr);
String fullShortUrl = domain + "/" + suffix;
if(!ShortUriCreateCachePenetrationBloomFilter.contains(fullShortUrl)){
//布隆过滤器认为短链接不存在
ShortUriCreateCachePenetrationBloomFilter.add(fullShortUrl);
return suffix;
}
attempt++;
}
throw new ServiceException("生成短链接繁忙,请稍后重试");
}
6.8 实现短链接分表
我们短链接肯定有海量数据,所以这里我们也对其进行分表
如下是生成分表SQL语句的脚本,不再赘述
1 | public class LinkTableShardingTest { |
- 下面我们来配置
shardingsphere- 这里我们分片键选择使用gid,而不使用短链接进行分组,因为我们查询的时候就是按照gid去查找短链接
1 | server: |
1 | # 数据源集合 |
6.9 实现短链接分页查询
用户查询短链接的时候,我们不能将所有能搜索到的短链接一并返回给用户,如果数据过多,会导致性能的消耗。
- 所以这里我们将搜索到的短链接进行分页。
首先创建实现分页查询所需要的请求和返回参数
- 这里请求参数需要三个参数: 分组标识,当前页数,分页大小
- 这里默认页数为
1,大小为10。 - 也就是说如果用户没指定页数和分页大小,默认显示第一页也就是前十个数据。
- 这里排序我们之后再进行优化
1 | package com.yin_bo_.shortlink.project.dto.req; |
1 | package com.yin_bo_.shortlink.project.dto.resp; |
- 接下来我们来写业务代码,具体就是将查询匹配的数据,当前页数,分页大小组装到一个page当中,再通过convert将其转变为collect,返回给用户。
- 注意 返回给用户还是一个page
1 | /** |
1 | /** |
1 |
|
6.10 后管调用中台短链
短链接业务逻辑在中台,如果我们想执行就必须调用中台接口。
- 我们需要在后管里远程调用中台的接口,这样用户只需要向后管发起请求就可以实现业务
远程调用业务逻辑我们使用
hutool里的HttpUtil,等之后服务变多之后再换成Openfeign或者Dubbo
- 在后管定义短链接Controller
1 | /** |
- 在后管remote包里编写 请求/相应DTO(直接复制中台的) , HTTP调用函数 , 短链接远程服务
1 | /** |
1 | /** |
- 现在我们可以使用后管API来调用中台里的短链接相关服务了。
- 用户访问服务的具体流程为:
- 前端 -> 后管Controller -> 后管远程Service -> 中台Controller -> 中台Service
6.10 短链接组分表
- 我们用户刚创建的时候,必须要有一个默认的短链接分组。
- 既然每个新用户都要有分组,那么我们的短链分组也需要分表
- 实际开发中可能每个新用户需要十几个短链接组,所以我们短链接组的表需要更多。
- 这里学习为目的也只分了16张表
- 以下是短链分组分表脚本
1 | public static final String SQL = "create table t_group_%d\n" + |
短链分组 分表的话,用什么做分片键呢?
- 如果用户要查询所有分组的话,我们不能使用gid去查
- 所以我们要用username作为分片键
我们的逻辑代码写在后管,我们需要在后管sharding-config里配置group表的分片键
1 | t_group: |
6.11 查看分组短链数量
该功能实现了以下功能
- 用户可以通过发送若干组的gid来查看组内的短链数量
下面是实现该功能的代码
- 请求gid的list
- 返回Maps,包括gid和组内短链数。
1 | /** |
1 |
|
1 |
|
1 | /** |
1 | /** |
上面功能返回的是一个Map的集合,也就是
List<Map<String,Object>>
selectList是将wrapper映射成List<>
而selectMaps是将wrapper映射成List<Map<String,Object>>
所以实现代码使用的是selectMaps然后将其回调到后管模块,这里不再赘述代码。
6.12 更正创建短链接功能
创建短链接功能有一些问题,那就是如果创建短链接的gid不存在,也会创建该短链接
- 这就需要查询gid是否存在的功能,若gid不存在则报错。
可是我们短链接模块只能查询是否存在拥有该gid的短链接
- 所以我们需要将分组模块引入到中台,并且在sharding配置里添加分表
1 | /** |
1 | package com.yin_bo_.shortlink.project.dao.mapper; |
- 因为我们分组的分片键是username,所以需要在中台添加没有拦截功能的用户上下文
- 当我们后管调用中台服务的时候
- 前端给后管传参,所以我们需要后管给中台传用户信息,否则用户信息存储不到中台的上下文
- 当我们后管调用中台服务的时候
1 | /** |
1 | /** |
1 | /** |
1 | /** |
- 然后完成gid是否存在的代码
1 | /** |
1 |
|
- 然后修改创建短链接代码
- 现在gid不存在时会抛出异常
1 |
|
6.13 修改短链接
修改短链接可以修改以下参数
- 域名
- 原始URL
- 网站图标
- 是否有过期时间
- 过期时间
- 描述
- 组表示
其中组标识因为是我们短链接的分片键,所以不能直接修改
- 我们需要先将带有旧的gid的短链接删除,再添加一个带有新的gid的短链接。
- 需要加
@Transactional(rollbackFor = Exception.class),保证事物一致性。
这里不使用逻辑删除
- 因为我们短链接的完整URL是唯一索引,不能修改
- 同一分片下不能有两个相同的URL
下面是实现代码
1 |
|
6.14 短链接跳转
我们来实现短链接跳转的功能
功能的实现如下:
- 用户输入短链接
- 通过Nginx代理到中台服务
- 获取到短链接对应原始网站
- 发送一个302重定向
虽然很简单,但是我们要考虑以下问题
- 缓存穿透:大量用户访问缓存和数据库中不存在短链接,数据库压力骤增
- 缓存击穿:短时间大量请求访问一个缓存过期短链接,数据库压力骤增
- 缓存雪崩:短时间大量短链接缓存失效,数据库压力骤增
先来创建短链接业务
- 用户只会向服务器传短链接uri,然后我们可以通过serverName获取域名。
- 也就是我们唯一可以获得的就是完整url
- 我们如果使用布隆过滤器进行判断是否存在,可能会误判,所以我们还需要查询缓存
- 那么问题来了,我们短链接的分片键是gid,然后我们查询短链接需要gid和完整url两个参数,我们应该如何获取gid呢?
- 用户只会向服务器传短链接uri,然后我们可以通过serverName获取域名。
我们就需要创建一个路由表
link_route- 只存
full_short_urlgidenable_statusdel_flag - 用
full_short_url查路由表拿gid - 再用
gid+full_short_url查t_link
- 只存
以下是判断短链接是否存在的逻辑
- 查询缓存
- 缓存miss -> 查路由表拿gid
- 再查t_link拿origin_url
- 标题: SaaS短链接
- 作者: yin_bo_
- 创建于 : 2025-12-05 12:07:20
- 更新于 : 2026-03-01 22:48:24
- 链接: https://www.blog.yinbo.xyz/2025/12/05/项目/SaaS短链接系统/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。